But if you Add Agents… You’ve Got Agentic RAG — A Real Killer! 🚀
Welcome to a deep-dive blog series where we explore Retrieval-Augmented Generation (RAG) and how combining it with Agentic behavior unlocks a new generation of AI solutions — ones that think, plan, and act in the real world.
📌 Why This Series?
2024 was the year of RAG.
I’ve seen almost every enterprise, startup, and innovation lab I’ve worked with or spoken to build something with RAG — from internal copilots to customer support bots and beyond.
But here’s the kicker: 2025 will be the year of Agentic RAG.
In this series, you’ll learn:
- How RAG actually works (beyond buzzwords)
- What Agentic RAG really means
- How to architect scalable, production-grade RAG + Agent solutions
- And why this is the next paradigm in applied AI
🔍 First, What is RAG?
RAG = Retrieval-Augmented Generation
It’s a method where a language model (like GPT or Azure OpenAI) is combined with a retrieval system to bring in external, domain-specific knowledge at runtime.
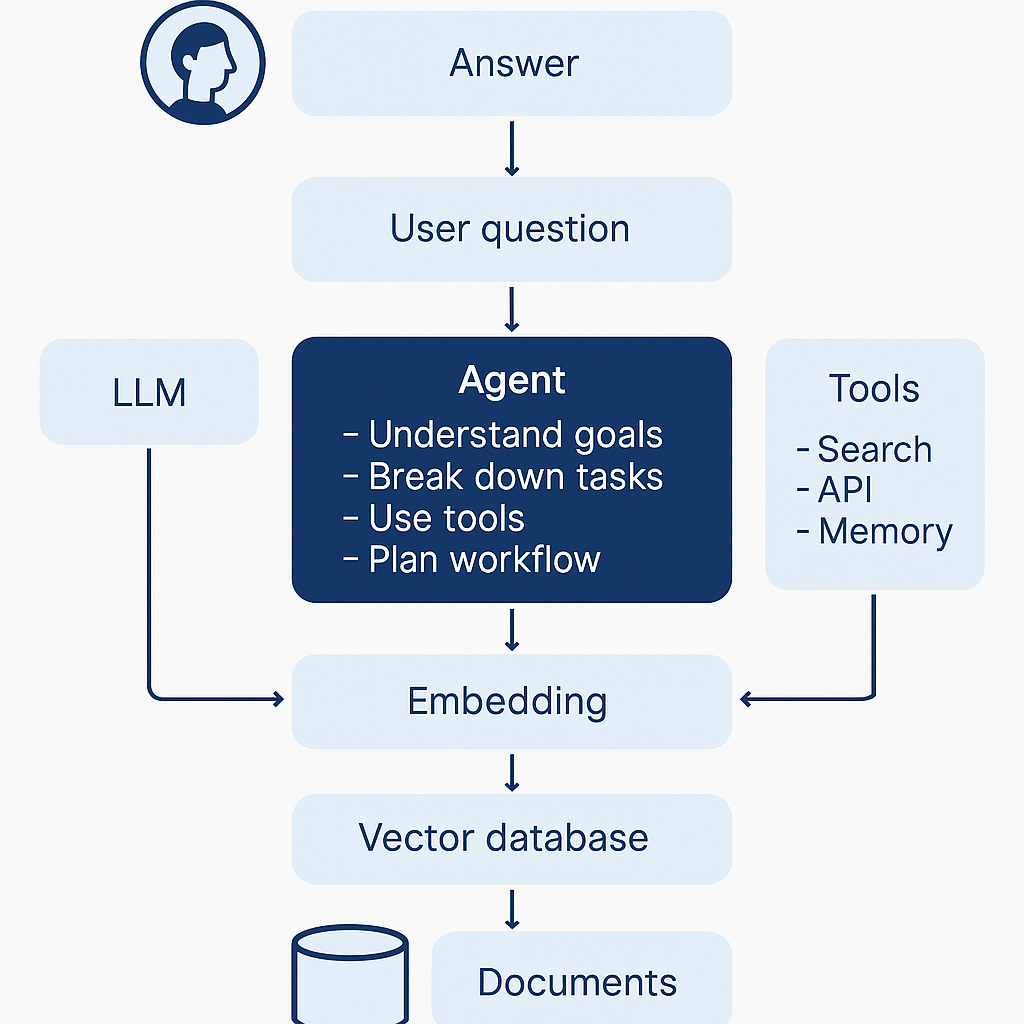
The Flow of a Typical RAG System:
- User asks a question
- RAG converts the question to an embedding
- The embedding is used to retrieve top matching content chunks from a vector database
- The retrieved chunks + original prompt are passed into an LLM
- The LLM generates a grounded, context-rich response
🗂️ Embeddings + Vector DBs: The Heart of RAG
Any RAG solution starts with embedding your data — turning unstructured content (PDFs, docs, webpages, etc.) into vector representations using models like:
text-embedding-ada-002(OpenAI)Instructor-XL,BGE, orMiniLM(open source)
Once transformed, you store these vectors in a vector database (vectorDB) like:
- Weaviate 🧡 (open source, local & cloud, schema-rich)
- Pinecone
- Qdrant
- ChromaDB
- Azure Cognitive Search (for Microsoft stack)
💡 Shout-out to the Weaviate team from the Netherlands 🇳🇱 — they’ve built an amazing platform with flexibility, hybrid search, and great community support.
🧩 But RAG ≠ Just Retrieval
The classic RAG pipeline works fine — but when you scale up:
- Large corpora (millions of docs)
- Complex data types (tables, charts, nested structures)
- Advanced workflows (multi-turn conversations, synthesis)
…it gets tricky.
That’s when you start needing:
- Chunking strategies (sliding windows, hierarchical chunking)
- Metadata filtering
- Re-ranking algorithms
- Context window optimizers
And even then, your RAG system still reacts, it doesn’t reason or plan.
🤖 Enter Agentic RAG: Where Magic Happens
Agentic RAG = RAG + LLM-based Agents (memory, tools, actions, goals)
Imagine your AI doesn’t just retrieve facts but:
- Breaks down user goals into subtasks
- Chooses the best tool for each
- Fetches documents, queries APIs, summarizes, and reports
- Remembers past interactions
- Asks clarifying questions when needed
Now you’ve got a system that isn’t just informative, it’s interactive, proactive, and autonomous.
🔧 Common Tools in Agentic RAG:
- LangChain / Semantic Kernel / AutoGen / CrewAI
- LLM Orchestration (Azure Functions, Logic Apps)
- Azure OpenAI Service + Cognitive Search + Function Calling
- Tool usage: Search, summarize, write, calculate, call APIs
🔗 Excellent Resources on Scaling RAG
Here are a few must-read resources from the community:
- RAG at Scale – Weaviate & Haystack Playbooks
- LangChain Agents and Tool Use Guides
- OpenAI Function Calling in Production
- Microsoft’s AI Architecture for Enterprise RAG
I’ll be breaking down these in future parts of this series, with real code snippets and architecture diagrams.
🧭 What’s Next?
In Part 2, we’ll build a simple RAG system using:
- OpenAI embeddings
- Weaviate vector DB (hosted or local)
- Azure Functions as orchestrators
- And LangChain to compose it all
Then, we’ll evolve that into an Agentic RAG Copilot — where your AI can:
- Search documents
- Write summaries
- Send emails
- Trigger workflows
🔥Too Long; Didn’t Read
- RAG gives your LLM facts to ground responses
- Vector DBs (like Weaviate) are crucial for fast, smart retrieval
- Agentic RAG turns your system into an AI teammate, not just a chatbot
- 2024 was RAG’s breakout. 2025 is for Agents + RAG = Autonomous AI
🏁 Follow the Series
Stay tuned for:
- 📦 Part 2: “Your First RAG Project with Azure + Weaviate”
- 🤖 Part 3: “Adding Agentic Capabilities with LangChain Agents”
- 🚀 Part 4: “Deploying Agentic RAG in Production with Azure AI Stack”
For References:
✔ Vanilla RAG: https://lnkd.in/dPf3x92e
✔ Advanced RAG: https://lnkd.in/dPVa7enW
✔ Multi modal RAG: https://lnkd.in/dkBkJqEt
✔ Agentic RAG: https://lnkd.in/dtM9FMHA
✔ Overview on RAG evaluation
✔ Agentic RAG ebook: https://lnkd.in/dr9qsGgH
It includes extensive explanation and code implementations 🙌

Leave a comment