
by Abhishek Kumar | FirstCrazyDeveloper
System design interviews often go beyond “How would you scale this system?” — they test how deeply you understand scalability, consistency, fault tolerance, and efficiency.
Behind almost every modern distributed system — whether it’s Google Search, Netflix streaming, Amazon DynamoDB, or Git — lies a set of fundamental algorithms and principles. If you understand these, you can explain trade-offs clearly and impress interviewers with practical knowledge.
Here are the Top 7 System Design Algorithms you must know, along with real-world use cases.
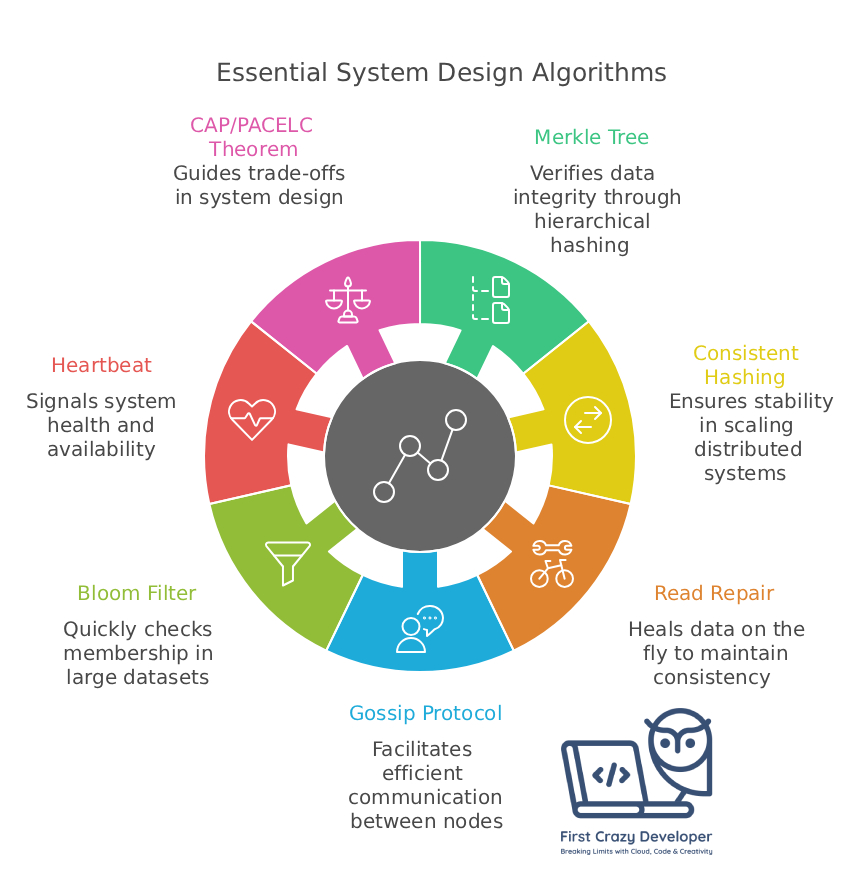
1. 🌳 Merkle Tree – Verifying Data Integrity
What it is:
A Merkle Tree is a hash-based hierarchical data structure. Each leaf node is a hash of a data block, and parent nodes are hashes of their children. At the top, a single “Merkle Root” summarizes the integrity of the entire dataset.
Why it matters in system design:
- Ensures data consistency across replicas.
- Makes verification efficient — instead of comparing entire datasets, you just compare hashes.
Real-world use cases:
- Git: When you
git commit, the data is stored as a Merkle Tree. Comparing branches is efficient because only hashes need to be checked. - Blockchain (Bitcoin, Ethereum): Verifies whether a transaction is part of a block without downloading the whole chain.
Interview tip:
If asked: “How would you verify data integrity in a distributed file storage system?” → Mention Merkle Trees for efficient integrity checks.

2. 🎯 Consistent Hashing – Stability in Scaling
What it is:
Consistent Hashing maps both servers (nodes) and data onto a ring structure. When a node joins or leaves, only a small portion of keys need to be reassigned — unlike traditional hashing, which remaps almost everything.
Why it matters in system design:
- Minimizes data movement when scaling up or down.
- Ensures load balancing with minimal disruption.
Real-world use cases:
- Amazon DynamoDB, Apache Cassandra: Store and retrieve data efficiently even when nodes fail.
- CDNs (Content Delivery Networks): Route requests to the nearest available cache server.
Interview tip:
If asked: “How would you handle a dynamic cluster where servers keep joining and leaving?” → Answer with Consistent Hashing to ensure stable distribution of keys.

3. 🔧 Read Repair – Healing Data on the Fly
What it is:
In distributed systems, replicas may become inconsistent (due to network delays or crashes). Read Repair means that when a client reads data, the system checks all replicas, compares results, and updates the stale ones.
Why it matters in system design:
- Ensures eventual consistency without heavy background processes.
- Keeps frequently read data fresh.
Real-world use cases:
- Cassandra, DynamoDB: When a client reads from multiple replicas, the system fixes outdated copies in the background.
Interview tip:
If asked: “How would you handle stale or inconsistent replicas in a distributed database?” → Discuss Read Repair as a lightweight consistency mechanism.

4. 🌐 Gossip Protocol – Efficient Cluster Communication
What it is:
Instead of a central node broadcasting updates, each node randomly shares information with others. Over time, all nodes converge towards the same state.
Why it matters in system design:
- Fully decentralized → no single point of failure.
- Scales well for large clusters.
Real-world use cases:
- Cassandra & DynamoDB: Nodes use gossip to share cluster membership and failure information.
- Epidemiology modeling (fun fact!): Similar to how diseases spread — fast and decentralized.
Interview tip:
If asked: “How would nodes in a distributed database keep track of which nodes are alive or dead?” → Suggest Gossip Protocol for failure detection and cluster membership.

5. ⚡ Bloom Filter – Space-Efficient Membership Check
What it is:
A Bloom Filter is a probabilistic data structure that answers: “Is this element in the set?” It may return false positives, but never false negatives.
Why it matters in system design:
- Saves time and space for large-scale lookups.
- Useful when exact precision isn’t critical.
Real-world use cases:
- Google Bigtable, HBase, Cassandra: Before checking disk, Bloom Filters check if a key might exist. If the filter says “no,” the system avoids costly I/O.
- Web browsers: Google Chrome uses Bloom Filters to quickly check malicious URLs.
Interview tip:
If asked: “How would you quickly check if a key exists in a huge database without loading everything into memory?” → Mention Bloom Filters.

6. ❤️ Heartbeat – System Health Monitoring
What it is:
A heartbeat signal is a lightweight ping between nodes to check if they’re alive. If a node stops sending heartbeats, the system assumes it has failed.
Why it matters in system design:
- Detects failures in real-time.
- Triggers failover and recovery mechanisms.
Real-world use cases:
- Kubernetes: The control plane sends heartbeats to nodes; if one stops responding, pods are rescheduled elsewhere.
- ZooKeeper, Hadoop YARN: Nodes send periodic heartbeats to confirm health.
Interview tip:
If asked: “How would your system detect server failures?” → Explain Heartbeat mechanism and how it enables automatic failover.

7. ⚖️ CAP & PACELC Theorem – The Trade-Offs of Distributed Systems
What it is:
- CAP Theorem: A distributed system can only provide two out of three guarantees:
- Consistency (every node sees the same data)
- Availability (system always responds)
- Partition tolerance (system works even if network splits)
- PACELC Theorem: Extends CAP by stating that even when there’s no partition, you must choose between Latency (L) and Consistency (C).
Why it matters in system design:
- Helps you justify design choices in interviews.
- No system can achieve all properties perfectly — trade-offs are inevitable.
Real-world use cases:
- CP Systems (Consistency + Partition tolerance): HBase, MongoDB (with strong consistency settings).
- AP Systems (Availability + Partition tolerance): Cassandra, DynamoDB (favor availability over consistency).
- PACELC explains why Amazon DynamoDB often prefers low latency (AP) while Google Spanner prioritizes strong consistency (CP).
Interview tip:
If asked: “Would you design a banking system as AP or CP?” → Answer: CP (Consistency + Partition Tolerance), because correctness of balances is more important than availability.

🔑 Final Takeaways
System design isn’t about memorizing buzzwords — it’s about knowing when to apply which concept.
- Use Merkle Trees for integrity verification.
- Use Consistent Hashing for scaling clusters.
- Use Read Repair for self-healing databases.
- Use Gossip Protocol for efficient communication.
- Use Bloom Filters for fast lookups.
- Use Heartbeat for detecting failures.
- Use CAP/PACELC Theorem to justify trade-offs.

💡 Pro Interview Tip: Always pair theory with real-world use cases. Interviewers love when you say: “This is how it works in Cassandra / DynamoDB / Kubernetes.”
✍️ Written by Abhishek Kumar | #FirstCrazyDeveloper
#SystemDesign #Algorithms #DistributedSystems #InterviewPreparation #CloudComputing #TechCareers #Scalability #SoftwareArchitecture #AbhishekKumar #FirstCrazyDeveloper

Leave a comment