
by Abhishek Kumar #FirstCrazyDeveloper
Modern applications are powered by real-time data. Whether it’s Netflix recommending the next show, Uber matching riders with drivers, or a bank detecting fraudulent transactions instantly—behind the scenes, there’s always a data streaming engine moving information from point A to point B at lightning speed.
For years, Apache Kafka has been the trusted backbone for these systems. But running Kafka at scale is expensive and complex, especially in the cloud era. Enter AutoMQ, a reimagined version of Kafka built for the cloud, designed to be cheaper, easier to scale, and simpler to operate.
Let’s break this down step by step, with real-world scenarios to make things concrete.
🔹 What is Apache Kafka?
Think of Kafka as a highway system for data.
- Producers are like trucks carrying packages (messages).
- Topics are lanes on the highway (e.g., Tech, Music, Gaming).
- Brokers are toll booths that manage the flow of traffic and store packages temporarily.
- Consumers are warehouses that unload and use the packages.
Kafka ensures that these trucks (messages) don’t collide, arrive in the right lane, and can be delivered even if a toll booth (broker) goes down.

Real-world Example:
Imagine you’re running an e-commerce platform like Amazon.
- Every click, search, and order generates events.
- Kafka collects these events in real-time.
- A “Recommendation Service” consumes user activity from Kafka topics to suggest products.
- A “Fraud Detection Service” consumes payment data to identify suspicious behavior instantly.
Kafka allows all these services to work in parallel on the same stream of events.
Strengths of Kafka
✅ Can handle millions of events per second.
✅ Fault-tolerant: If one broker dies, data is still safe due to replication.
✅ Mature ecosystem with tools like Kafka Streams, Connectors, and ksqlDB.
Limitations of Kafka
❌ Complex to operate: Scaling requires manual partition reassignment (like re-routing highway lanes while traffic is still moving).
❌ High costs: Each piece of data is copied multiple times across brokers for fault tolerance, consuming lots of storage and network bandwidth.
❌ Slow scaling: Adding brokers isn’t instant—it can take hours or days to rebalance traffic.
🔹 What is AutoMQ?
AutoMQ takes Kafka’s model but redesigns it for the cloud era.
The biggest innovation? Separating compute (brokers) from storage (data).
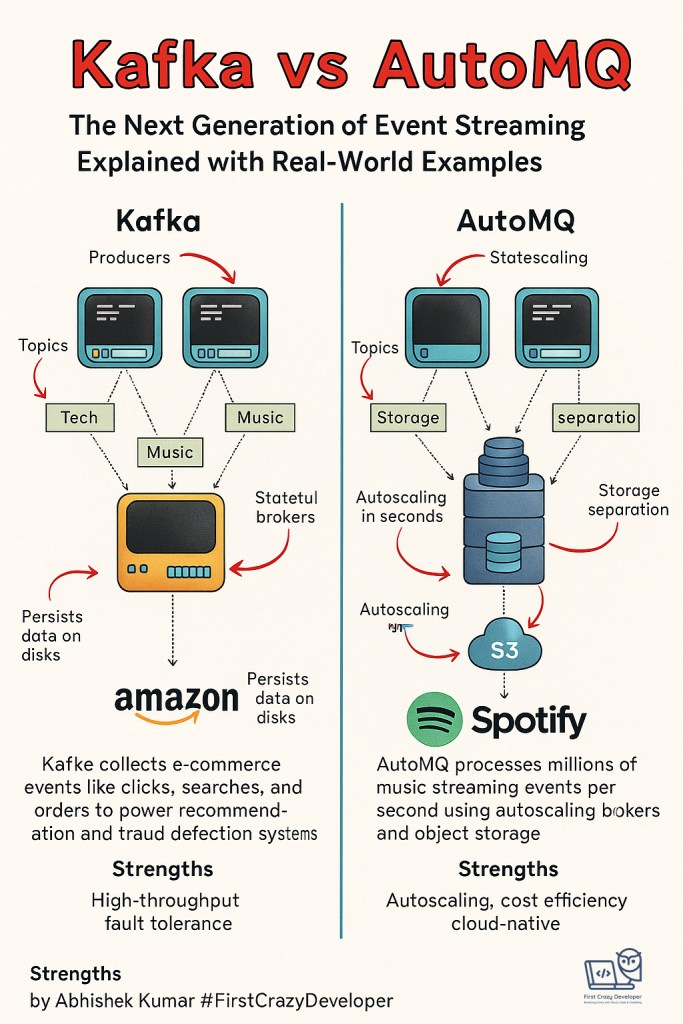
Instead of brokers being stateful (responsible for storing data on disks and managing replicas), AutoMQ brokers are stateless. All data is stored in cloud object storage like Amazon S3.
This is like upgrading from a toll booth with local storage to a cloud-connected smart toll system where trucks (messages) drop their cargo into a giant, shared cloud warehouse.

Real-world Example:
Imagine you’re running Spotify.
- Millions of users are streaming songs every second.
- Each “play event” (user presses play) is logged.
- With Kafka, brokers store these logs on their own disks, requiring replication and large clusters to avoid data loss.
- With AutoMQ, brokers just pass events directly into S3, which already has multi-region replication built-in.
Result: Spotify doesn’t have to maintain massive clusters with expensive disks—saving millions of dollars in cloud costs.
🔹 How AutoMQ Improves Kafka
- Stateless Brokers
- Kafka brokers are “heavy” because they store partitions. AutoMQ brokers are “light” and stateless—they just forward data to storage.
- Scaling is instant: if Spotify suddenly sees traffic spike during a Taylor Swift album release, AutoMQ can add brokers in seconds.
- Storage-Compute Separation
- Kafka = tightly coupled (storage + compute).
- AutoMQ = decoupled (storage on S3, compute in brokers).
- This means you don’t pay for unused compute just to keep storage alive.
- Lower Costs
- AutoMQ cuts 90% of Kafka costs by using cheap cloud storage instead of local broker disks + replicas.
- Example: A financial trading platform storing 100 TB of tick data could spend $1M/year on Kafka storage. AutoMQ on S3 may reduce this to $100K/year.
- Elastic Scaling
- Kafka scaling = rebalancing partitions → downtime or degraded performance.
- AutoMQ scaling = spin up new brokers instantly (like adding new checkout counters during Black Friday).
- Data Lake Integration
- With Kafka, you need ETL (Extract-Transform-Load) jobs to move data into data lakes like Iceberg.
- With AutoMQ, you can stream directly into an Iceberg table without ETL.
- Example: A retail company analyzing purchase trends in near real-time.
🔹 Side-by-Side Comparison: Kafka vs AutoMQ
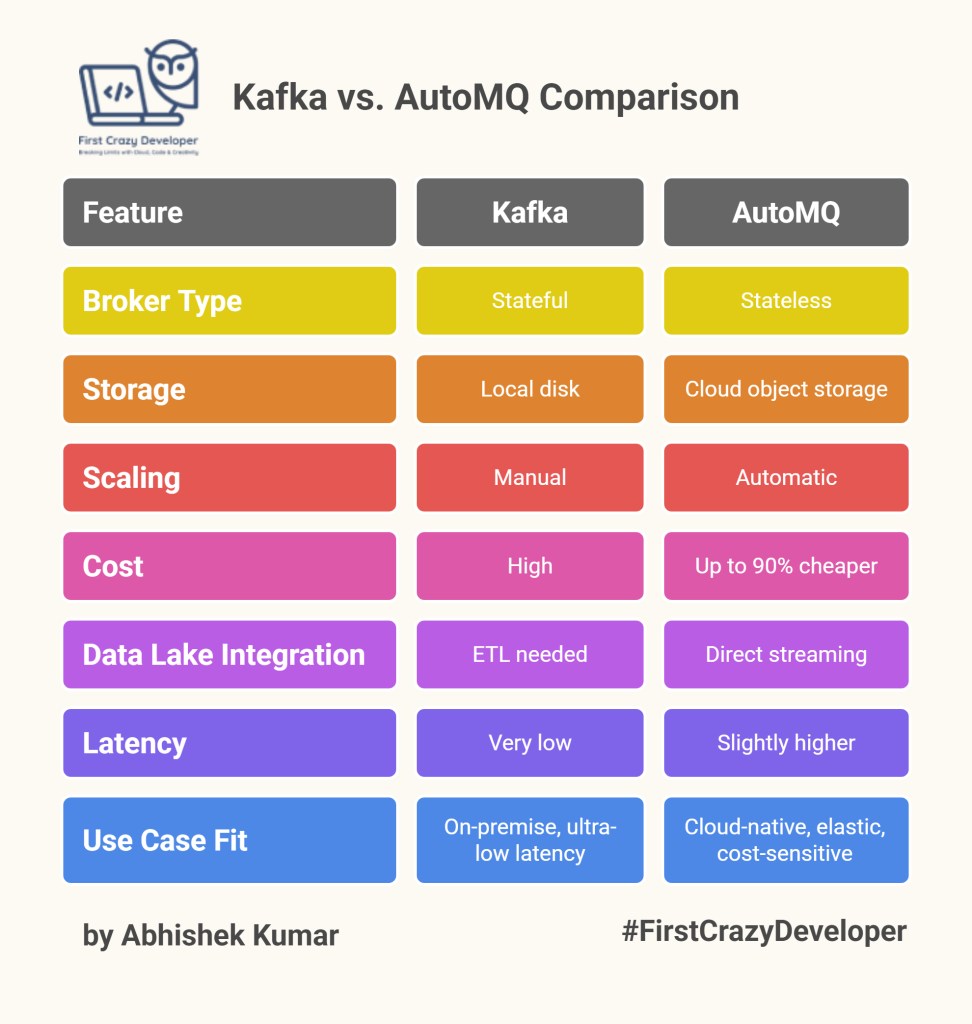
| Feature | Kafka | AutoMQ |
|---|---|---|
| Broker Type | Stateful (stores partitions on disks) | Stateless (just forwards to cloud storage) |
| Storage | Local disk + partition replicas | Cloud object storage (S3, built-in replication) |
| Scaling | Manual, downtime-prone | Automatic, in seconds |
| Cost | High (compute + storage + replication) | Up to 90% cheaper |
| Data Lake Integration | ETL needed | Direct streaming into Iceberg tables |
| Latency | Very low | Slightly higher (commercial AutoMQ offers <10ms writes) |
| Use Case Fit | On-premise, ultra-low latency workloads | Cloud-native, elastic, cost-sensitive workloads |
🔹 When to Choose Kafka vs AutoMQ
Choose Kafka if:
- You run on-premise infrastructure and can manage local storage.
- You require ultra-low latency (e.g., high-frequency trading systems).
- Your team has strong Kafka expertise and tooling already in place.
Choose AutoMQ if:
- You’re operating in the cloud and want to cut costs.
- Your workloads are elastic (e.g., holiday e-commerce traffic spikes).
- You want simpler operations without managing replication or partition reassignments.
- You’re building data lake integrations for analytics.
🔹 Abhishek Take
Kafka is like the old reliable engine—powerful but heavy, requiring constant tuning and expensive fuel. AutoMQ is the electric upgrade—lighter, cheaper, and built for today’s cloud highways.
The choice isn’t “Kafka OR AutoMQ” but which tool fits your environment.
- For legacy, low-latency, on-prem workloads → Kafka still shines.
- For cloud-native, elastic, cost-sensitive architectures → AutoMQ is the future.
As more enterprises embrace cloud-native event streaming, I believe AutoMQ will play the same role in the 2020s that Kafka played in the 2010s: a game-changer in how we move data at scale.
✍️ By Abhishek Kumar | #FirstCrazyDeveloper
#AbhishekKumar #Kafka #AutoMQ #CloudNative #EventStreaming #ApacheKafka #DataEngineering #BigData #RealTimeAnalytics #Scalability

Leave a comment