This document explores two powerful patterns in Azure for improving application availability: Zone Redundancy (ZR) within a region and Multi-Region High Availability (MR-HA) across regions. It provides a decision matrix to help you choose the right approach based on cost, latency, RTO/RPO, and operational complexity, along with reference architectures, code examples, and testing strategies. The document also covers common pitfalls and offers practical tips for cost optimization and performance.
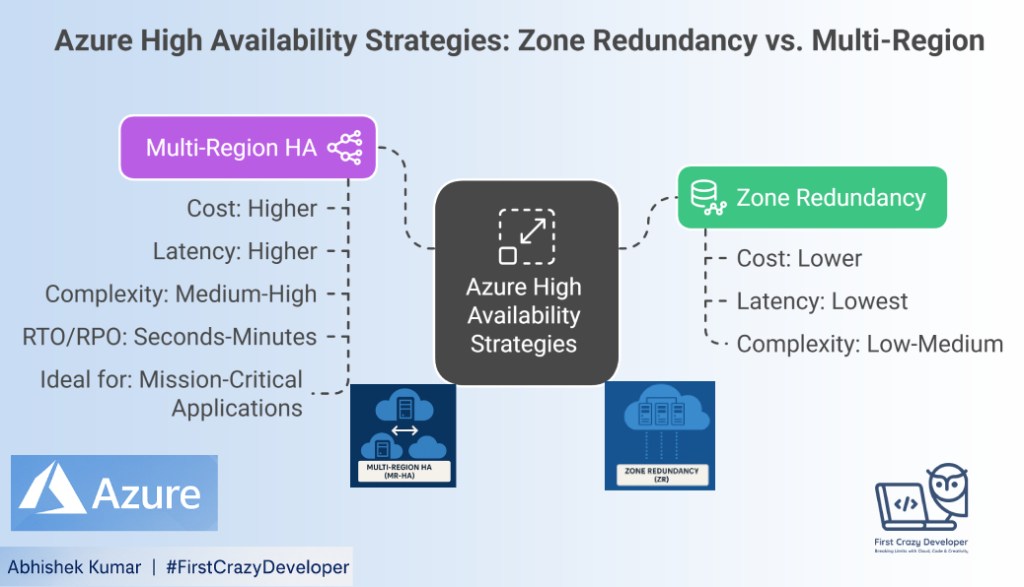
Downtime can significantly impact revenue and erode customer trust. Azure offers two primary strategies to enhance application availability: Zone Redundancy (ZR) and Multi-Region High Availability (MR-HA). Selecting the appropriate strategy is crucial, as it directly affects cost, latency, Recovery Time Objective (RTO), Recovery Point Objective (RPO), and operational complexity.
⚡Decision Matrix
Criterion
Zone Redundancy (ZR)
Multi-Region HA (MR-HA)
Scope of failure tolerated
Single datacenter (AZ)
Full regional outage
Latency
Lowest (in-region)
Higher (cross-region)
Complexity
Low–Medium
Medium–High
Cost
Lower
Higher (duplicate infra + data egress)
RTO/RPO (typical)
Minutes/near-zero
Seconds–minutes / seconds–minutes
Ideal for
Most prod workloads needing 99.99%
Mission-critical, regulatory, DR mandates
⚡Core Concepts (in 60 seconds)
Availability Zone (AZ): Physically separate datacenters inside one Azure region.
Zone Redundancy: Distribute replicas across 3 AZs in the same region (e.g., westeurope AZ1/2/3).
Multi-Region HA: Replicate to a paired or secondary region (e.g., westeurope ⇄ northeurope). Survives full regional failure.
⚡Reference Architectures
A) Zone-Redundant Web App (Same Region)
Front Door or Azure Application Gateway (zonal or zone-redundant)
App Service (Zone Redundant) on PremiumV3/IsolatedV2 (scale across AZs)
Azure SQL DB (Zone Redundant) or Cosmos DB (multi-AZ)
Storage (ZRS) for static assets
Private DNS + Private Endpoints for data plane
When to use: Low latency, resilient to a datacenter loss, simpler ops.
B) Multi-Region Active/Passive (Two Regions)
Region A (Primary) + Region B (Secondary)
Azure Front Door for global anycast + health probes + failover
App Service in both regions (slot warm in secondary)
⚡Azure CLI: Multi-Region SQL Auto-Failover Group (A→B)
# Variables
PRIMARY_RG=rg-we
SECONDARY_RG=rg-ne
PRIMARY_LOC=westeurope
SECONDARY_LOC=northeurope
SQL_PRIMARY=fcdevsqlwe
SQL_SECONDARY=fcdevsqlne
DB=appdb
FOG=myfog
# Create secondary server
az sql server create -g $SECONDARY_RG -n $SQL_SECONDARY -l $SECONDARY_LOC \
-u $SQL_ADMIN -p $SQL_PWD
# Geo-replicate DB
az sql db replica create -g $PRIMARY_RG -s $SQL_PRIMARY -n $DB \
--partner-server $SQL_SECONDARY --partner-resource-group $SECONDARY_RG
# Failover group
az sql failover-group create -g $PRIMARY_RG -s $SQL_PRIMARY \
-n $FOG --partner-server $SQL_SECONDARY \
--add-db $DB --failover-policy Automatic --grace-period 1
⚡Cosmos DB: Multi-Region with Preferred Writes (C# & Python)
🔹C# SDK
using Microsoft.Azure.Cosmos;
var accountEndpoint = Environment.GetEnvironmentVariable("COSMOS_URI");
var key = Environment.GetEnvironmentVariable("COSMOS_KEY");
var client = new CosmosClient(accountEndpoint, key, new CosmosClientOptions {
ApplicationPreferredRegions = new[] { "West Europe", "North Europe" },
AllowBulkExecution = true,
EnableTcpConnectionEndpointRediscovery = true
});
// Read with region preference
var container = client.GetContainer("appdb", "items");
var response = await container.ReadItemAsync<dynamic>("id1", new PartitionKey("pk1"));
Console.WriteLine($"RU: {response.RequestCharge}");
Tip: For MR-HA, enable multi-region writes if you need active/active; otherwise keep write region single and use automatic failover.
⚡Storage Strategy
ZR only:ZRS for hot path; lifecycle to Cool/Archive.
MR-HA:GZRS/RA-GZRS for geo-redundant + zone-redundant.
Avoid cross-region chatter in hot paths; cache near users.
🔹Front Door + App Service (Multi-Region Routing)
Use Azure Front Door (Standard/Premium) for:
Anycast global entry, WAF, path routing
Health probes to fail from Region A to B
Origin groups: App Service endpoints in each region
Keep session state stateless or use Redis Cache geo-replication / sticky only if necessary.
🔹Testing Playbook (Print-worthy)
Zone fail test: Stop instances in AZ1; verify app stays up.
Region fail test: Block Front Door origin A; observe failover to B (<1–2 min).
Data RPO test: Write storm → trigger failover → validate last commit.
DNS/Certs: Ensure wildcard certs in both origins; short TTL.
Runbooks: Document manual failover (SQL FOG, Cosmos manual) and rollback.
Chaos drills: Quarterly game days; record RTO/RPO evidence.
🔹Cost & Performance Tips
ZR → best value for 95% of apps.
MR-HA → budget for duplicate compute + egress; turn down secondary to warm (autoscale min=1), not cold.
Prefer read-heavy offload to secondary region where users are.
Log Analytics retention by need (e.g., 30–90 days) and export to Blob for long-term.
🔹Common Gotchas
Stateful services without cross-region session design.
Private Endpoints not duplicated in secondary (breaks failover).
Key Vault not enabled with soft-delete + purge protection.
Regional features: some SKUs not GA in both regions—check parity.
✨Abhishek Take
Start with Zone Redundancy as your default. Add Multi-Region HA only when there’s a real business driver (RTO/RPO, regulatory DR, global latency). Keep apps stateless, standardize runbooks, and practice failovers—that’s what separates check-box DR from real resilience.


Leave a comment