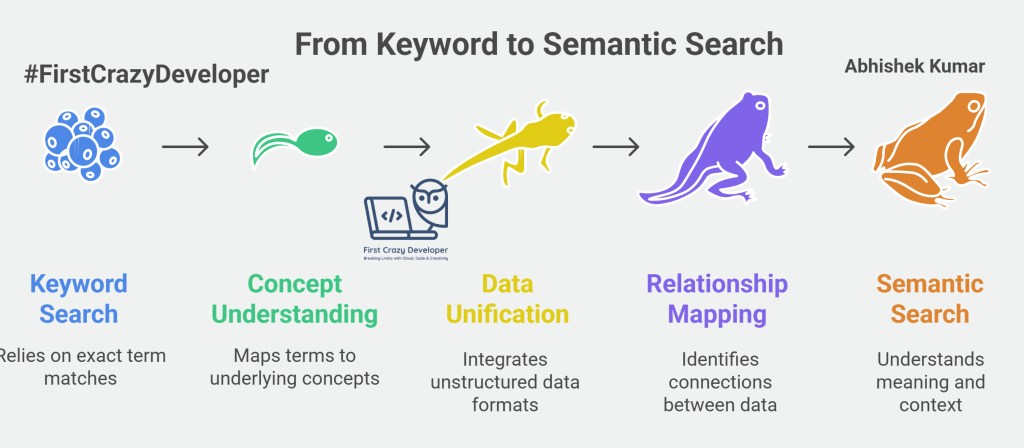
Traditional databases store structured data (rows & columns) and perform keyword or pattern matching. But AI systems don’t think in keywords — they think in meanings.
For example:
Searching “Top Gun” in SQL might return only exact word matches.
A vector database, however, understands context — “Top Gun” ≈ “Maverick,” ≈ “fighter pilot,” ≈ “Tom Cruise.”
That’s why modern AI systems like ChatGPT, RAG pipelines, and semantic search engines rely on vector storage and retrieval — to find the closest meaning, not the closest word.
Semantic Search Understands Concepts, Not Keywords
Engineers often search with different terms:
“flash point”
“ignition temp”
“flammability threshold”
Semantic search links these automatically — no need for exact strings. This eliminates misses caused by inconsistent terminology across labs, plants, or suppliers.
Removes Dependency on Human Naming Conventions
Every engineer names files differently:
“TDS_rev3_final_FINAL.pdf”
“PaintSpec_2024_New”
“BatchReport_12_A_Fix.csv”
With semantic search, engineers search by meaning:
“low viscosity resin for high humidity conditions” not by filename.
Automatically Maps Similar Formulations & Materials
Semantic search clusters:
similar resin types
similar pigment compositions
similar solvent blends
Perfect for:
formulation benchmarking
cross-product equivalence
R&D ingredient substitute suggestions
Works Across Unstructured Data (PDFs, Images, Tables)
Manufacturing data is messy:
TDS + MSDS PDFs
Lab notebooks
QC reports
Sensor logs
Safety guidelines
Scan images of batch forms
Semantic search embeds all data — giving one unified discovery layer.
Finds Related Failures Even If Logs Are Written Differently
Maintenance logs are inconsistent:
“pump cav.”
“cavitation at inlet”
“air bubbles @ intake”
“low NPSH issue”
Semantic search understands all are related → faster diagnosis → reduced downtime.
Semantic search cuts this down drastically → faster innovation cycle.
Identifies Research Patterns That Humans Miss
Embedding similarity can automatically detect:
repeated failure patterns
recurring behaviour in experiments
parameter setups that lead to consistent results
hidden relationships in material properties
This is impossible with keyword search.
Forms the Basis for Knowledge Graphs
Semantic vectors are perfect building blocks for:
product lineage graph
material-property graph
research insight graph
Engineers can query:
“What raw materials influence gloss retention in exterior coatings?”
This is next-gen manufacturing intelligence.
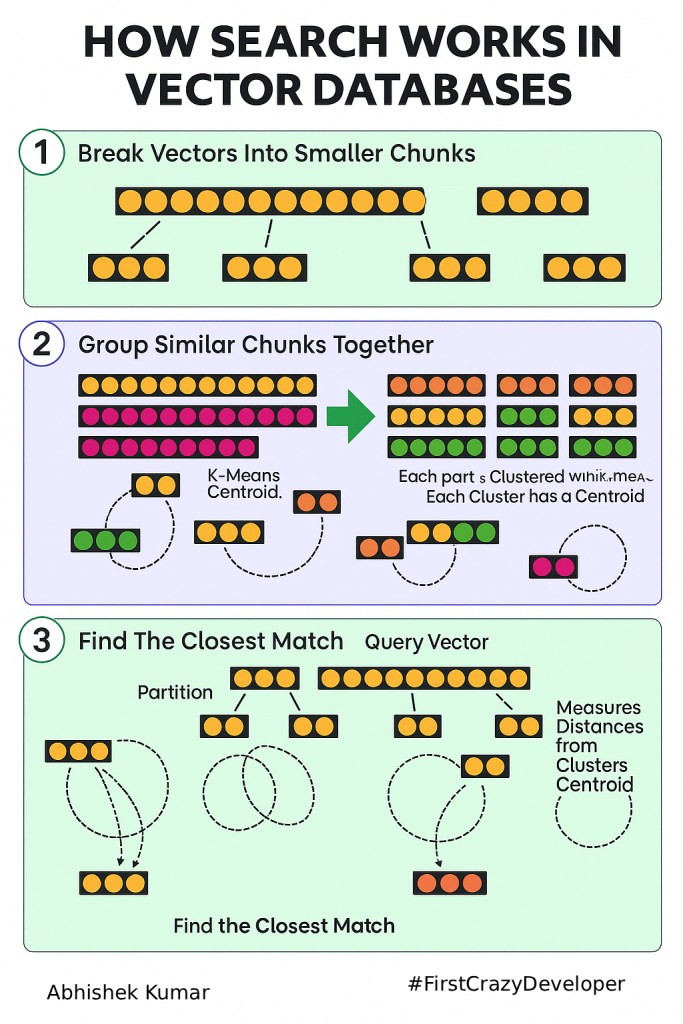
🧩 Step 1 – Break Vectors Into Smaller Chunks
When you insert data (a document, an image, or a transcript), it’s first converted into an embedding vector — a long list of numbers representing its meaning.
Example using OpenAI Embeddings in Python:
from openai import OpenAI
client = OpenAI()
text = "Top Gun is a movie about a fighter pilot named Maverick."
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
vector = response.data[0].embedding
print(len(vector)) # e.g. 1536 dimensions
But these vectors can be very long (hundreds or thousands of dimensions). So, systems like FAISS split them into smaller sub-vectors for easier processing.
👉 Each chunk captures a portion of meaning (like topic, sentiment, or subject).
🧮 Step 2 – Group Similar Chunks Together (K-Means Clustering)
Once vectors are created, they’re grouped using clustering algorithms such as K-Means.
Each cluster has a centroid — the mathematical “center” representing all items inside it.
Similar chunks (e.g., all “fighter jet” or “aviation movie” contexts) stay together.
This makes searches much faster. Instead of checking millions of vectors, the system first finds the nearest centroids and only searches inside those relevant clusters.
Example using FAISS + K-Means
import faiss
import numpy as np
# Suppose we have 10,000 vectors, each 128-dim
data = np.random.random((10000, 128)).astype('float32')
# Create 10 clusters
num_clusters = 10
kmeans = faiss.Kmeans(d=128, k=num_clusters, niter=20, verbose=True)
kmeans.train(data)
print("Centroids shape:", kmeans.centroids.shape)
Now, your vector database knows “where to look” — a massive speed boost.
🎯 Step 3 – Find the Closest Match for Your Query
When you type a query like “Top Gun,” it’s also converted into a vector. Then the database:
Finds which cluster centroids are nearest to your query vector.
Calculates the distance (often cosine similarity or Euclidean distance).
Returns the vectors with the smallest distance — the closest meanings.
Example: Searching “Top Gun”
# Assume FAISS index built from movie embeddings
index = faiss.IndexFlatL2(128)
index.add(data)
query = np.random.random((1, 128)).astype('float32')
distances, indices = index.search(query, k=5)
print("Closest matches:", indices)
Behind the scenes:
The query vector is compared to cluster centroids.
The nearest vectors (e.g., Maverick, Fighter Pilot, Tom Cruise Movie) are returned.
These results are sorted by semantic closeness, not by keywords.
🏗️ Real-World Example – Semantic Search in RAG Pipeline
Imagine an enterprise knowledge base with thousands of documents.
A user asks:
“Show me safety guidelines for solvent handling in paint factories.”
Here’s how the pipeline works:
The query → embedding vector.
The system finds similar vectors (documents) via the vector database.
The most relevant context is retrieved and fed to an LLM (like GPT-4 or Llama 3).
The model generates an answer — grounded in real company knowledge.
Minimal LangChain Implementation
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
embeddings = OpenAIEmbeddings()
db = FAISS.from_texts(["Maverick is a fighter pilot.", "Top Gun is a movie."], embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(model="gpt-4o-mini")
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
print(qa.invoke({"query": "Who is Maverick?"}))
This is the core of modern AI memory — searching by meaning instead of by words.
⚡ Benefits of Vector Search
Advantage
Description
Semantic Understanding
Finds conceptually related results — not just exact text.
Scalability
Handles millions of vectors using FAISS IVF, HNSW, or Milvus indexes.
Speed
Narrow search space through cluster centroids → faster retrieval.
Multi-Modal Search
Works for text, images, audio, even code embeddings.
Foundation for RAG & AI Agents
Enables intelligent retrieval in chatbots, Copilots, and decision systems.
💡 Will Vector Databases Replace Traditional Search?
Not entirely — but they’ll dominate semantic and AI-driven contexts.
SQL Search = Exact Match
Vector Search = Meaning Match
Hybrid Search = Best of Both
Future enterprise systems will use hybrid search — combining structured SQL queries (filters, metadata) with semantic vector search for meaning.
⚙️ Why Semantic Search is Important in the Manufacturing Domain and Research
Understanding Complex, Domain-Specific Data
In manufacturing, data lives everywhere — Product specifications, safety sheets, SOPs, machine logs, formulations, quality reports, and research papers.
Traditional keyword search struggles with:
Synonyms (“Toluene” vs “Solvent A”)
Context (“Drying time” vs “Curing duration”)
Multilingual documents
Semantic Search solves this by understanding meaning. A query like “safe handling for paint thinners” will retrieve documents mentioning “solvent safety instructions” — even if the term “paint thinner” never appears.
Accelerating R&D and Innovation
In research labs and formulation teams:
Thousands of technical papers, test results, and patents exist.
Engineers waste hours searching PDFs or SharePoint folders.
With vector databases (like Milvus, Pinecone, or Azure Cognitive Search with embeddings):
“Find studies on corrosion resistance of zinc coatings” → retrieves results like “anti-rust performance of galvanized steel”
This helps reduce duplicate experiments, accelerate formulation discovery, and improve knowledge reuse across plants.
Connecting Cross-Disciplinary Knowledge
Manufacturing blends chemistry, physics, and engineering. Semantic search bridges these silos:
A material scientist searching “resin viscosity control” might find relevant process optimization papers from production engineers.
A sustainability researcher looking for “VOC reduction techniques” can discover paint formulations with “low-solvent composition”.
Result → Smarter innovation through knowledge connection.
Empowering AI Agents and RAG Systems
Semantic search is the core of Retrieval-Augmented Generation (RAG). In manufacturing, RAG-powered copilots can:
Answer “What are the recommended drying parameters for Product X?”
Suggest “alternative raw materials with equivalent viscosity index.”
Retrieve “all safety incidents related to solvent storage.”
Without semantic search, such systems can’t understand intent or meaning.
Enhancing Predictive Maintenance and Troubleshooting
Machine maintenance logs are unstructured and full of abbreviations:
“Pump cav issue @ high RPM” ≈ “Cavitation problem at high speed.”
Semantic search maps this linguistic chaos into meaning — helping find similar failure patterns, predictive maintenance reports, or sensor anomalies faster.
Real-World Example
At a chemical companies, a semantic vector database could:
Store all TDS, MSDS, formulation sheets, and lab reports as vectors.
Allow engineers to ask: “Show all formulations with low-VOC and fast drying time.”
Return relevant PDFs — even if they mention “volatile organic compound reduced resin with accelerated curing” instead of “low VOC fast dry.”
That’s contextual intelligence in action.
⭐ Summary for Engineers (One-Liners)
Semantic search = meaning match, not keyword match.
Embeddings convert every file into a comparable numeric format.
Helps engineers retrieve correct info faster & more accurately.
Works across PDFs, tables, images, scans, logs.
Enables AI copilots (RAG) for manufacturing & R&D.
Connects similar materials, formulations, failures automatically.
🧠 Abhishek Take
“Semantic search in manufacturing isn’t just about faster lookup — it’s about creating a knowledge graph of meaning across products, plants, and people. It turns decades of research into instantly accessible intelligence.”
✨ Final Thought
If you understand vector search, you understand the foundation of AI retrieval.
Next time you search “Top Gun” and instantly get “Maverick,” remember — it wasn’t magic. It was math + meaning at work.

Leave a comment