Category: Database Design
-
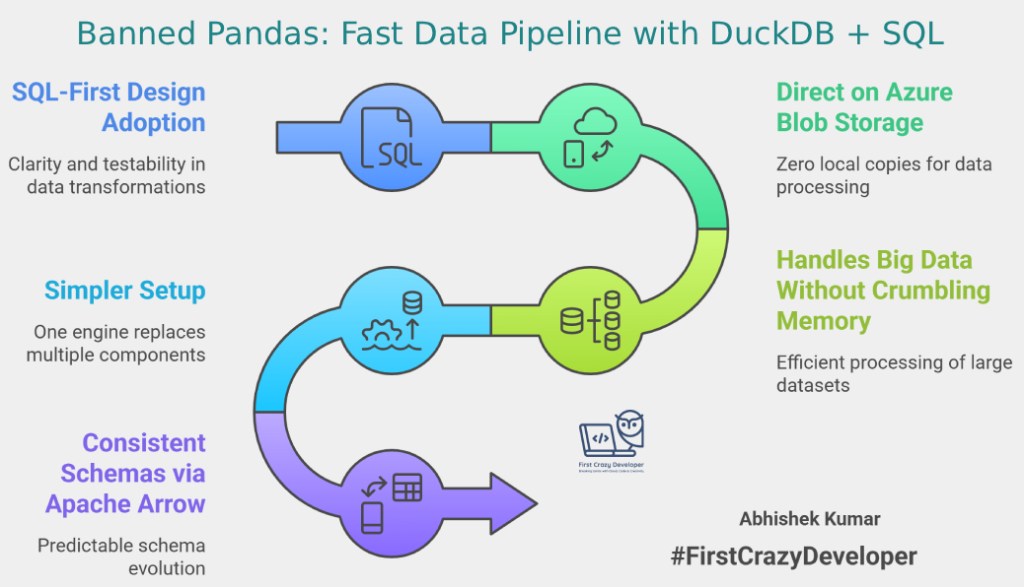
✍️ By Abhishek Kumar | #FirstCrazyDeveloper 🧠 Why This Change Matters Our data pipelines were fast — until they weren’t.Large joins started crashing memory, inconsistent datetime types caused nightly job failures, and debugging hidden Python logic in Jupyter notebooks became a nightmare. So, we did something radical. We banned pandas.Every transformation now runs in DuckDB,…
-
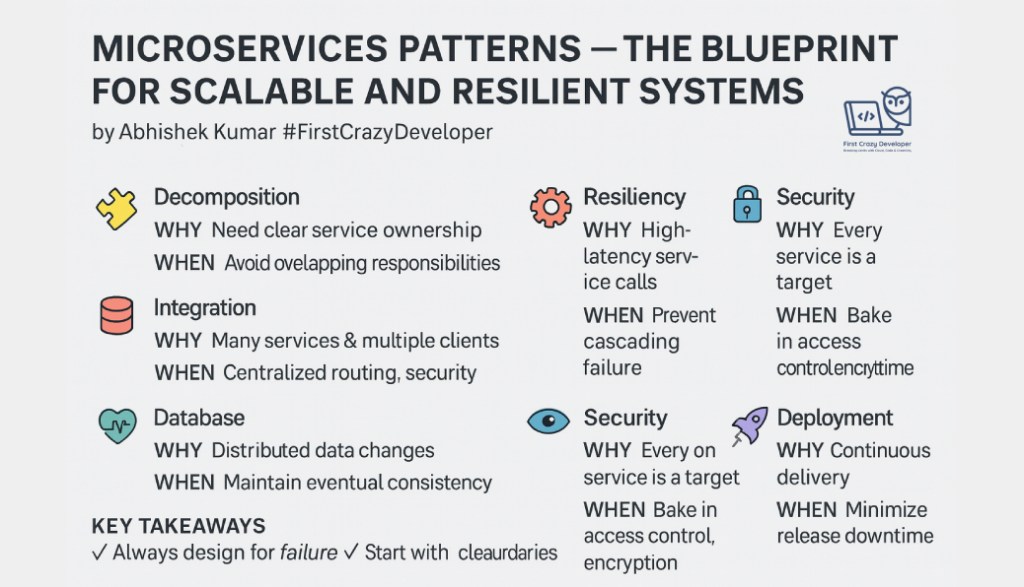
✍️ By Abhishek Kumar | #firstcrazydeveloper Microservices Architecture Leads to Chaos — Unless Designed Right Microservices are like independent puzzle pieces of a large system — each one performs a specific task, communicates through well-defined APIs, and can be deployed independently. When done right, microservices enable rapid scaling, continuous delivery, and fault isolation. But when…
-
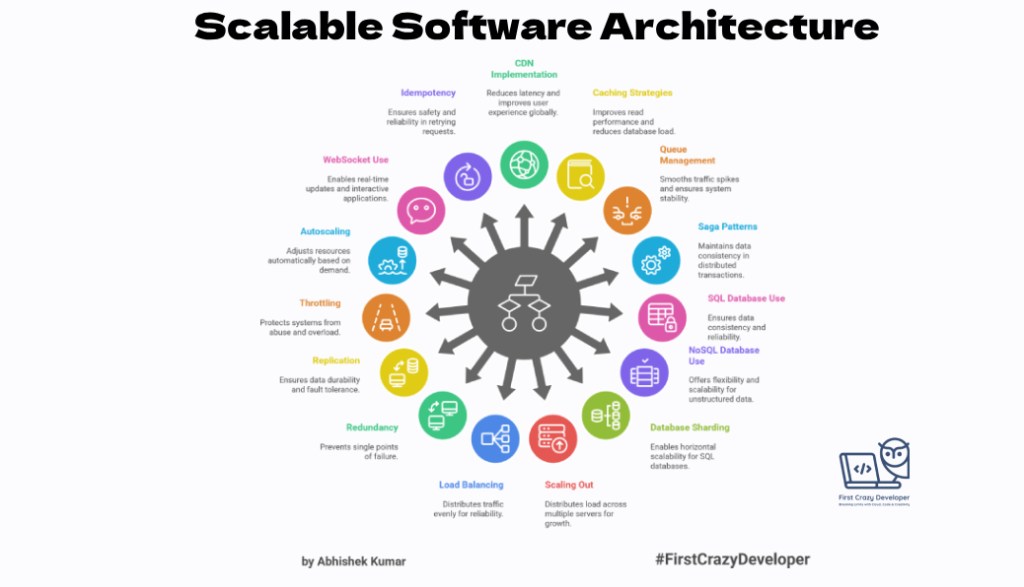
✍️ Abhishek Kumar | #FirstCrazyDeveloper When building large-scale systems, the challenge isn’t just about writing clean code—it’s about designing for scale, resilience, and performance. This is where system design heuristics come into play. They act as guiding principles to make smart decisions when architecting software. In this blog, we’ll break down 15 key heuristics, explain…
-

by Abhishek Kumar | FirstCrazyDeveloper Choosing the right database isn’t just a backend decision—it’s a strategic move that directly impacts application speed, scalability, and flexibility. Whether you’re building a financial system, a social app, or an AI-powered platform, your database is the backbone that determines how efficiently your solution runs. In this guide, let’s explore 14…
